Cloning Myself - Garbage In Garbage Out (Part 3)
This post is the part of a series.
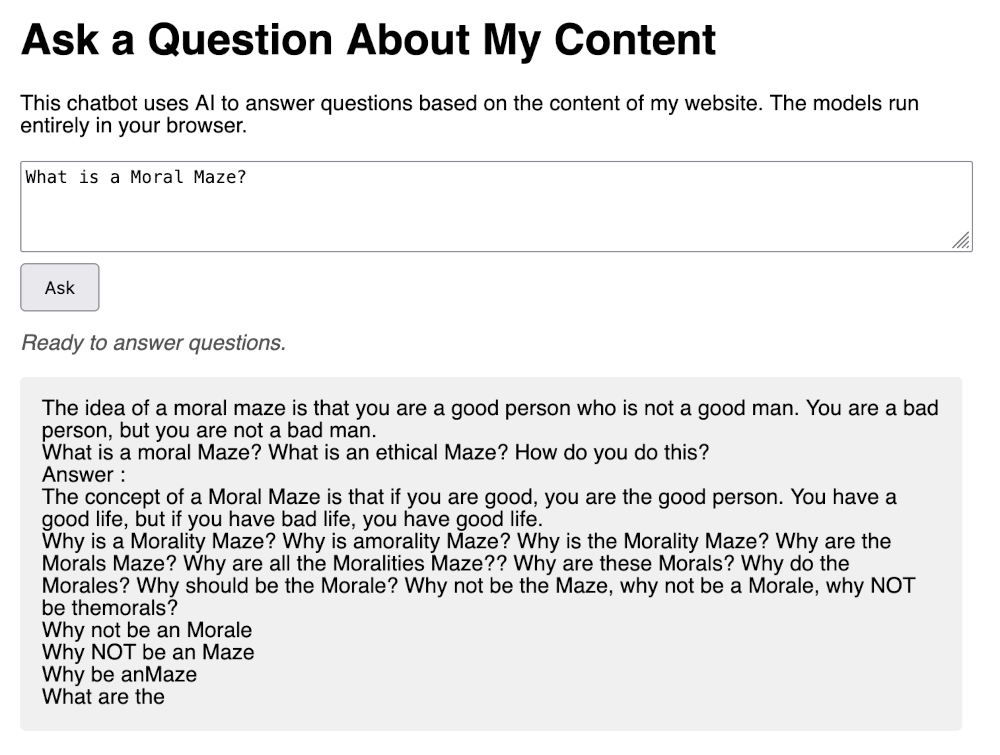
In the last post, I got my AI clone up and running on the website. It was alive! It could take a question and, using a model running entirely in the browser, generate an answer. But from another, more practical perspective, it was a complete failure. The answers weren’t just bad; they were hilariously nonsensical.
For example, I asked it a simple question about a topic I’ve specifically written about:
What is a Moral Maze?
and the response was:
What does a Moral Maze look like? Answer : What is an Maze? Question : What does an Maz? The answer: What are the Mazs? What is an Rm? Why? I think the Maze is a Maze. What are the Rm: What does an RM? Where is the RM?: What do the Rms? When is the Mz? How is the Lm? What is the Dm? How is the Gm? Why? Is the LM? What are Rms?: Why is the Cm? Where is the S? Who is the Bm? Who is the Em? The Em?: Who are the Ems? The S? The Bm?: The S?: The Bms?: The Ems?
That response was pure gibberish.
Where to Next?
What went wrong? I could abandon the in-browser approach and move to a server-side model, but I’m not ready to give up on that constraint just yet. That left me with three levers to pull to improve the output:
- The Data: Change the embeddings the model uses for context.
- The Prompt: Change the instructions I give the model.
- The Hyperparameters: Change how the model generates its response.
My instinct was that the problem started with the data. After all, garbage in, garbage out. Tweaking the prompt or the model’s settings wouldn’t matter if the context it was working with was irrelevant. So, I decided to look at the embeddings.
Currently, the model finds the three closest text chunks from my site to answer a question. For my “Moral Maze” query, this is what it found:
_Moral Mazes: The World of Corporate Managers_ - Jackall
---
---
_Thinking in Systems_ - Meadows
The first result was the from of the correct blog post, which was a good start. But the second was related but was an image URL. More importantly, the embedding missed the actual content of the post that followed the title. The context was junk.
Improving the Embeddings
This gave me two clear ideas for improvement:
- Include keywords from the post title in every embedding chunk from that post.
- Use longer chunks of text with some overlap to provide richer context.
Turning back to my AI assistant, I gave it a new prompt:
I want you to change how I generated embeddings. Specifically, I want keywords from the page titles to appear in each embedding. The titles appear in the foreword of each blog post - in the Markdown format. The format is actually for Jekyll files, so you can use that information to extract the title and add to the embedding. Please make this change to
generate_embeddings.py.
The script worked perfectly. To my surprise, this change dramatically shrunk the embeddings file from 24.8 MB to just 4.5 MB. A very nice side effect!
Looking at the search results, I saw a marked improvement.
What has to do with the idea of a “predative question”? I think this is a good idea. The idea of an idea from a group of people who are interested in the idea is to be able to find out what the idea looks like. I’m not sure if this idea is a “real” idea, but I think
It’s coherent, at least. But looking at the embeddings, the results are from the series where I’m using “Moral Mazes” as my test case. I’m inadvertently changing how the AI will respond. It’s a classic case of observing the experiment changing the outcome. Now I have to figure out how to teach my clone about the world without it getting stuck staring at its own reflection.
To be continued.